.svg)







.svg)







.svg)

.png)
Arcium presents a shared-secret caching optimization that significantly reduces latency for encrypted instructions with MXEs. Previously, every encrypted instruction required recomputing a Diffie-Hellman-derived shared secret in MPC, adding roughly 1 second of overhead per request. The new design separates shared-secret derivation from the main circuit execution and caches the result locally on cluster nodes as soon as the first interaction. As a result, repeat interactions between users and MXEs reuse cached secrets through lightweight local lookups, making encrypted applications like dark pools feel substantially more responsive while also reducing circuit size and freeing computation resources for application logic.
Introduction
Arcium is an encrypted computing network that provides trustless, scalable MPC-based execution over fully encrypted data for applications across blockchain, AI, enterprise, and government. The Arcium network consists of a multitude of MPC (Multi-Party Computation) clusters, each consisting of a handful of nodes. A cluster can process data while remaining encrypted throughout and without any (subset of) nodes ever seeing the clear data. For a program to interact with a cluster it needs to declare a set of (encrypted) instructions and initialize a MXE (Multiparty eXecution Environment). In the typical Alice and Bob setup, you can think of the MXE as Alice, and all the data Alice holds is processed by the cluster, i.e. remains encrypted as long as at least one node in the cluster is honest. As an example, let’s consider a dark pool program, where an encrypted order book is stored on-chain, and users will want to interact with that encrypted dark pool by sending encrypted orders. This is enabled via dedicated encrypted instructions. In this example, the MXE/cluster holds the private key to encrypt the order book (and no one but the MXE can decrypt it, but even when decrypted, no node can see the clear data). In addition, the MXE holds a private key/public key pair that enables users to interact with it creating a secure channel, that is, user and MXE both take their private key and the other party’s public key to perform a Diffie-Hellman key exchange to derive a common shared secret. Once the shared secret is established, both parties can encrypt data locally and send over unsecure channels, so the other party can decrypt. The only difference is that the MXE, despite acting like Alice in the standard picture, never sees any of the data it operates on, even after decrypting it. So as a user, you can encrypt your valuable data and send it to your trusted friend Alice, who will then process it securely.
Limitations
To meet stronger cryptographic requirements, the established shared secret is usually hashed with a secure cryptographic hash function. This operation, despite being incredibly rapid for the user, requires non-negligible compute resources for the MXE adding up to 1 second overhead per instruction. This additional latency can seriously harm the UX of the application for the users.
One possible optimization is to decouple the computation of the shared secret from the actual computation, i.e., inserting the order into the order book, in combination with a highly advanced caching logic on the node. Based on the circuit and the provided inputs, i.e. users' public keys, nodes can infer the client public keys used to derive a shared secret for. Each node in the cluster will then load its share of the cached shared secret. If any of the nodes does not have the (share of the) shared secret in cache for any of the users submitting encrypted data to the MXE, the cluster will first run the computation to compute the shared secret (again, while no subset of nodes actually sees the shared secret), have each node add it to the cache, and then run the actual computation. For upcoming interactions of the user with the MXE, the shared secret should be in the cache and hence, significantly speed-up the compute time.
Implementation
To support our advanced caching mechanism, we first reworked our internal Arcis compiler that now automatically detects whenever an instruction requires a user encrypted input, i.e., a shared secret which needs to be derived. For every instruction the developer implements, the compiler adds so-called Expressions to the Intermediate Representation (IR). When the instruction gets compiled, the compiler performs hefty optimizations on the IR and then outputs the circuit in a format the Arcis MPC engine can understand and process. Previously, the building block responsible for carrying out the computation of the shared secret was always inlined and added to the intermediate representation as a whole. This piece alone adds up to 1s overhead to the actual computation. With our latest optimization we no longer inline the entire key exchange by default. Instead we add a single Expression to the IR, carrying the shared secret information. Why n-th input public key and not the actual public key? The reason is that the circuit is compiled way before it is actually run for the first time, i.e. the user public keys are runtime values and are not known to the compiler. The place where both the runtime user-provided public keys and the compiled circuit come together is the node. Inspecting the circuit, the node can make the match between the static list of public keys needed for loading/deriving the shared secret for, and the actual input public keys provided to the circuit.
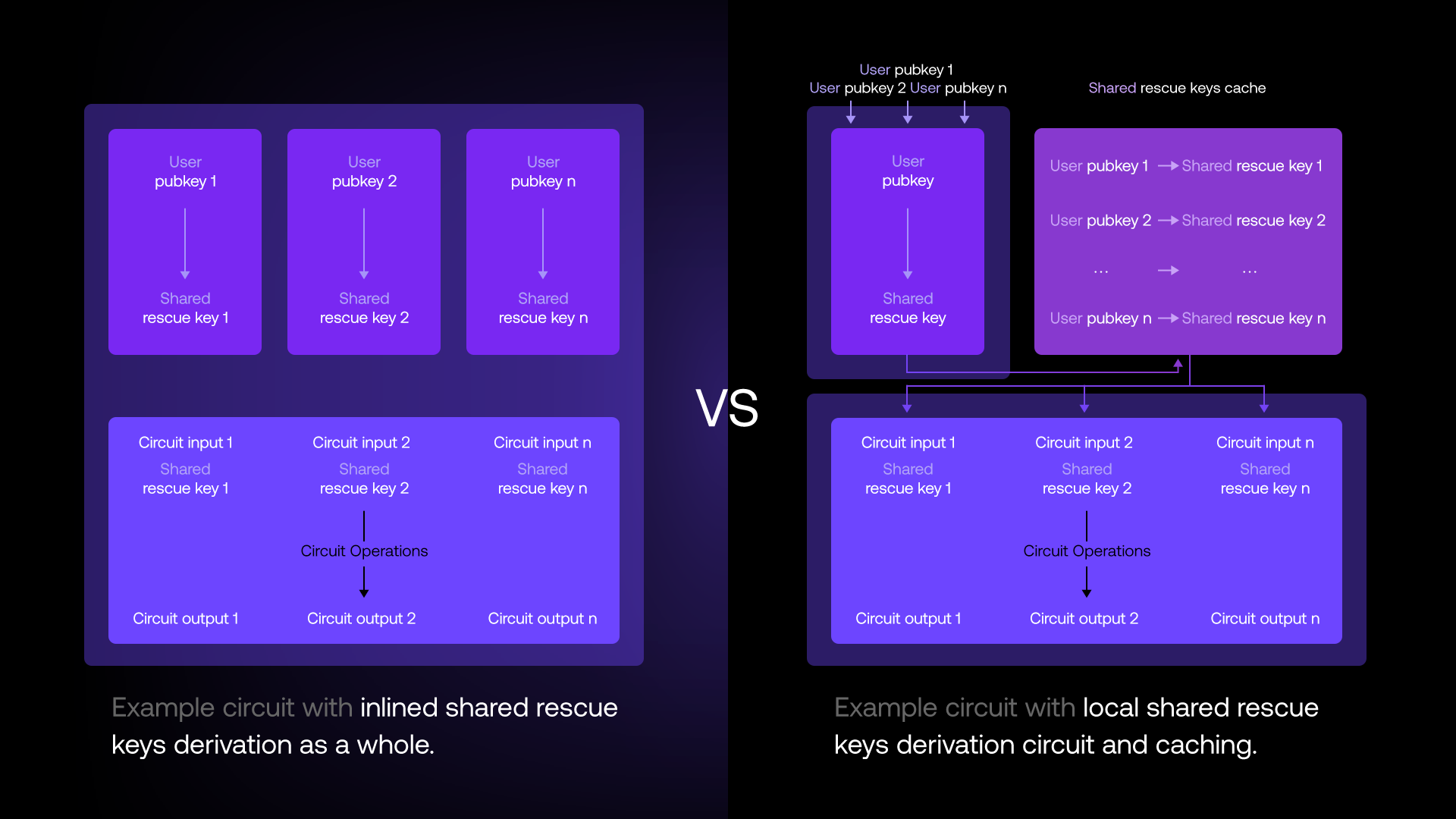
Improvements
What’s notable about this optimization is that it adds essentially zero perceived overhead in the worst case, and compounds into a significant win from the second use onward. Going back to the dark pool example, the first time a given user submits an encrypted order, nodes derive the shared secret like before but cache it for later reuses, then proceed to the actual encrypted order insertion. Every following interaction between that user and the dark pool, however, skips the key derivation entirely: nodes simply reuse their cached shared key and get straight to the actual work, i.e. inserting the encrypted order into the encrypted order book. Concretely, the shared secret derivation is a non-trivial MPC protocol between the nodes. In our current setup, this adds up to roughly 1 second overhead to every instruction. With the proposed optimization, after the first interaction that 1 second collapses into a single local cache lookup. For a user placing 10 orders in the dark pool, that is about 9 seconds of cumulative latency reclaimed.

A second win is a cleaner separation of concerns this introduces across the Arcium stack. Developers and the Arcis compiler no longer have to treat shared secret derivation as an inlined fragment of every circuit. Shared keys management is moved away from the developer and Arcis responsibility to where it actually lives, i.e. between the user and the cluster operating the MXE directly. As a side effect, circuits become lighter: as the shared key derivation is no longer compiled in the circuit, which results into smaller circuits, and more Arcium compute units freed up for the developer’s actual own logic inside the same instruction.
The change is also fully backwards compatible: nodes inspect each circuit and automatically pick the right path whether the shared key derivation is inlined or separate key derivation and caching.
For the users, the experience is entirely transparent. There is no new flow, simply the second order placed against the dark pool feels noticeably snappier than the first, and every order after that stays snappy. From the developer’s perspective, the upgrade is equally invisible at the code level: instructions don’t need to be rewritten, only rebuilt with the updated compiler. The gains, however, are very much visible: lower latency and a larger compute budget per instruction result in a smoother UX, which translates into more users, more activity for the MXE, and ultimately more opportunities built on top of that MXE. Node operators also benefit from the upgrade, trading a resource they have plenty of, i.e. local storage for caching, for the one they are actually bottlenecked on, i.e. bandwidth. The result is more instructions processed per unit of time on the same hardware, and correspondingly more revenue.
Challenges
Caching shared secrets is not without its own set of trade-offs, and the main one is straightforward: cache state grows with the number of distinct users interacting with a given MXE. For a popular dark pool with thousands of active traders, nodes have to keep a share of the shared secret per user, which adds up at scale and across the several MXEs nodes simultaneously serve.
Naive caching could open the door to a caching denial-of-service vector. A malicious user could repeatedly interact with an MXE under freshly generated keypairs, forcing nodes to derive brand new shared secrets for every single instruction and bloating the cache with entries that will never be reused.
The answer is a carefully designed cache eviction policy. Rather than treating all entries equally, the policy should reward repeated, legitimate usage, keeping the shared secrets in cache for users who actively interact with the MXE.
Release
Shared secret caching will ship as part of an upcoming Arcium release. Once live, developers will only need to rebuild their encrypted instructions using the latest CLI to start benefiting from the optimization on any cluster that will have upgraded to the matching node version. Existing deployments continue to work unchanged thanks to the backwards-compatible node logic described above, so the rollout is as smooth as necessary.























.jpg)





.jpg)

